
Как SEO-анализаторы переизобретают соседство слов под разными именами 👇
Ципф, косинусная близость, PMI и SWBM25 — это не четыре разные метрики. Это одна идея: слова, которые стоят рядом с ключом в документах топа, несут больший сигнал релевантности, чем частотность ключа самого по себе. Каждый инструмент называл её по-своему и мерял по-разному — но искал одно и то же.
Понимание того, что Ципф, PMI и SWBM25 считают одно и то же, меняет логику выбора инструмента: важна не метрика, а то, как конкретный сервис режет документ на зоны. Какой анализатор закрывает именно вашу задачу — по зонам, скорости и фокусу на шапку — разобрано в сводном разборе 22 текстовых анализаторов с разбивкой по задачам и поисковикам.
Что общего у всех этих метрик
Все четыре работают с соседством слов в документе — co-occurrence в разных формах. Ципф мерял распределение частот по всему корпусу и давал число: насколько «нормально» слово вписывается в текст по закону степенного распределения. Косинусная близость берёт вектор ключевого слова и смотрит, какие слова в документах конкурентов тянутся к нему в многомерном пространстве — и показывает конкретные слова, а не абстрактный балл. PMI (Pointwise Mutual Information) считает, как часто два слова встречаются вместе против того, как часто они встречались бы случайно — чем выше PMI, тем сильнее семантическая связь. SWBM25 в ГАР берёт N-граммы с наибольшим BM25-весом и смотрит, где они сосредоточены — в первую очередь в шапках сайтов конкурентов.
Разница одна: охват и визуализация.

Ципф — параметр без слов
Ципф в старых анализаторах давал число. Ты видел: «семантическая близость = 0.73». Что это значит — неясно. Какие конкретно слова стоят рядом с ключом у конкурентов — не видно. Параметр был, применить его к тексту было нельзя. Это нулевая точка эволюции метрики.

Косинусная близость — те же слова, но уже видно какие
Косинусная близость решила именно эту проблему визуализации. Вместо числа — список конкретных слов, семантически близких к ключу по корпусу конкурентов. Специалист видит: рядом с «хирургическим столом» в топах стоят «нержавеющая сталь», «дезинфекция», «нагрузка 250 кг». Их можно взять и встроить. Это тот шаг, который превратил метрику из измерительного инструмента в рабочий.

PMI — та же механика, другое агентство
PMI по математике — ближайший родственник косинусной. Он считает вероятность совместного появления двух слов в корпусе против их случайного появления. Агентство, о котором идёт речь, внедрило эту механику под своим названием — результат тот же: список слов, которые «тянутся» к ключу в текстах конкурентов. Нового здесь нет ничего — есть переупаковка под другой бренд.
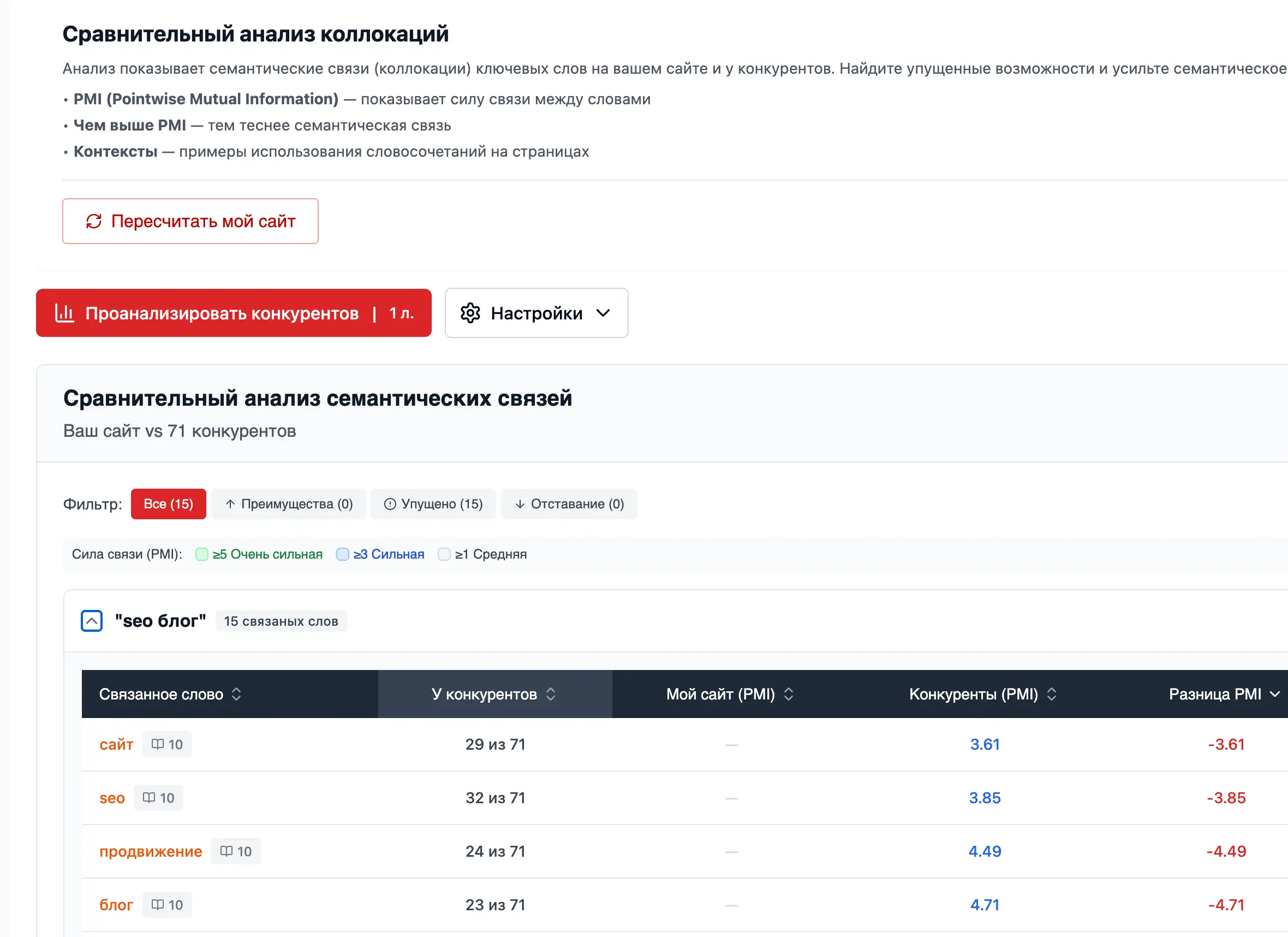
SWBM25 — единственное реальное отличие
SWBM25 в ГАР делает одну вещь, которой нет в базовой косинусной: он фокусируется на первых 50–200 словах документа — шапках сайтов конкурентов. Логика простая: Яндекс придаёт зонам документа разный вес, и начало страницы — это text-fragment зона с максимальным сигналом для passage ranking. Те N-граммы, которые конкуренты из топа держат в шапке — и есть самые сильные тезисы. SWBM25 их вытаскивает. Это не другая метрика — это та же co-occurrence, но с зонным приоритетом.
H2: В чём принципиальная разница
| Метрика | Охват документа | Что видит специалист | Можно вставить в текст |
|---|---|---|---|
| Ципф | весь корпус | число/балл | нет |
| Косинусная | весь документ | конкретные слова | да |
| PMI | весь документ | конкретные слова | да |
| SWBM25 | шапка (50–200 слов) | N-граммы с весом | да |
Ципф мерял, но не показывал. Косинусная показала слова. PMI повторила то же самое. SWBM25 добавила зонный фокус — единственный реальный сдвиг за всю эволюцию.
Почему одна идея переизобретается снова и снова
Потому что идея правильная. Слова, которые co-occur с ключом в документах, реально тянут релевантность. Это подтверждается и через BM25, и через нейросети (word2vec, GloVe строятся на тех же co-occurrence матрицах). Каждый новый инструмент приходит к ней своим путём — через статистику, через лингвистику, через патенты Яндекса — и называет своим именем. Это не плагиат и не наивность. Это конвергенция к одному правильному ответу.
Неочевидный момент: нейросетевые эмбеддинги (word2vec, BERT) — это тоже косинусная близость, только обученная на гигантских корпусах, а не на выдаче по одному запросу. NeuronWriter и SEO Agents под капотом делают то же самое, что Ципф в 2005 году — просто с лучшей моделью.
Что это значит для практики
Любой из инструментов даёт рабочий список слов. Разница — в детализации и зонности. Алгоритм работы одинаковый:
- Взять слова, которые стоят рядом с ключом у конкурентов из топа.
- Отсортировать по частоте появления и весу (BM25/PMI/косинус — неважно).
- Встроить в текст — особенно в первые 50–100 слов страницы.
- Для Яндекса — приоритет шапке (text-fragment зона).
Если под рукой только Ципф-параметр без слов — он бесполезен. Если есть косинусная, PMI или SWBM25 — инструменты эквивалентны по результату, разница только в удобстве извлечения N-грамм.
Неочевидные углы для усиления поста
- Ципф и word2vec — одна математика, 20 лет разницы: закон Ципфа — это степенное распределение частот, и именно на этом распределении строятся все современные языковые модели. Можно провести линию от Ципфа до BERT в три шага.
- Зонный фокус SWBM25 — это passage ranking: не просто «шапка важнее», а конкретный механизм Яндекса — ранжирование по фрагментам. Шапка весит больше не потому что «так сказал Маркин», а потому что это text-fragment зона по патентам.
- PMI — академическая метрика 1990 года: Church & Hanks придумали PMI для NLP ещё в 1990. Агентство, «внедрившее» её как новую фичу в SEO-анализатор — просто нашло правильный инструмент с запозданием на 30 лет.
- Провокационный тезис для вовлечения: «Все текстовые анализаторы считают одно и то же. Выбор инструмента — это выбор интерфейса, а не метрики».
Это набросок для этого поста в черновом формате лол:
Все статьи и новости →Короче, я подумал написать пост такое исследование. Дело в том, что я однажды написал косинусную близость в своём текстовом анализаторе. Я начал программисту дал задачу и определяю косинусную близость. Потом некоторые меня захейтили, что, мол, это не косинусная, что ты там это гонишь. В общем, это семантическая близость, а не косинусная. Ну, чтобы по правилам было, да, типа. И чуть позже я рассказал об этом, и ребята в одном агентстве, они себе внедрили и назвали это PMI. Вот. Но по сути это что-то похожее, тоже берутся слова недалеко от нашего слова искомого. Вот. Потом я взял анализатор Маркина Антона Гар и в их сообществе, и поковырял вот их функцию SWBM25 и посмотрел, что это практически то же самое, что и моя косинусная близость и семантическая, потому что по баллам она показала, что мои тезисы, которые я строил, одни из самых сильных. Единственный момент, что я в своём текстовом анализаторе косинусную близость снимаю по всему документу по самым, ну, часто повторяемым словам у всех конкурентов. Ну, по сути, это BM25. А у них SWBM25 в первую очередь они фокусируются, ну, то же самое, да, BM25 по документу, но они ещё фокусируются, насколько я понял, на первые там 50 или 200 слов шапках сайтов. То есть для них это ещё важно, чтобы эти тезисы были прям в шапках. Вот насчёт PMI я не углублялся, как работало в твоём агентстве, но суть я понял, что они повторили за мной и только как-то по-своему, типа правильнее. И вот недавно я общался с человеком, который текстовый анализатор себе сделал, и он туда из старых анализаторов древних взял вот этот параметр цыпко. И когда я у него спросил, что это такое, по сути, когда он мне объяснил, это и есть семантическая близость косинусная. То есть получается, что она когда-то раньше была, она вычислялась только в табличном виде, формате. И ну, никогда не показывала реальные данные, то есть никто не мог посмотреть, где какое слово возле какого, но все это как-то меряли этим, ну этими просто проценты там или что-то ещё цифровым значением. А у меня это можно прямо увидеть конкретные слова, применить, прописать вот эти ребята из PMI, которые внедрили. SWBM25 Антона Маркина тоже можно поддёргивать какие-то формулировки, может, не суперудобно, но, грубо говоря, что это было на заре, анализаторов просто как параметр в целом, да, он измерялся по всем конкурентам, так и сейчас он уже внедряется более детально, где можно что-то выдернуть и вставить. Вот, и я хочу, чтобы ты помог мне этот пост оформить.